Wie einfache Code-Optimierungen Ihre Prozesszeiten um ein Vielfaches optimieren können
Clean Code und die Vermeidung von unnötiger Speicherbelegung sind vor allem in Produktions-APIs und Anwendungen, bei denen es auf kurze Antwortzeiten ankommt, sehr wichtig. Obwohl Python aufgrund seines interpretierten Charakters nicht die schnellste Programmiersprache ist, bleibt es die go-to Programmiersprache für Machine Learning (ML)-Anwendungen.
Durch die Vielzahl der ausgereiften Packages wie PyTorch bietet sich die Sprache sehr gut an.
Die strategische Bedeutung von Code-Optimierung für Geschäftsanwendungen
Die eindeutigen Vorteile wie zum Beispiel die Verbesserung der Nutzererfahrung durch schnellere Response-Times, sind längst nicht das Wichtigste hinsichtlich Code-Optimierungen bei ML (Machine Learning) Anwendungen. Heutzutage sind vor allem Cloud-Anwendungen die Hauptlösung im ML-Bereich.
Die relativ einfache Installation über die Cloud bietet Anwendern und vor allem Start-Ups komplett neue Möglichkeiten - mit verbundenen Risiken.
Ein einfaches Beispiel dazu sind die anfangs kostenlosen Produkte, die auch bei wenigen Nutzern und kleinen Datenbanken relativ kostengünstig und einfach zu verwalten sind. Doch explodieren die Kosten bei mehreren tausend Nutzern sofort.
Dementsprechend wichtig sind dementsprechend die sogenannten Cost Management Setups um beispielsweise Alarme beim überschreiten von bestimmten Kostengrenzen zu senden.
Praktische Beispiele zum Thema Code-Optimierungen in ML-Anwendungen
Zu den bekanntesten Fehlern und Problemen gehört das Thema “Spaghetti-Code”. Dies entspricht Code, welcher schlecht wartbar ist und keinerlei Strukturen besitzt.
Klassisch beginnt man mit dem schreiben eines ML-Codes in einem Jupiter Notebook, in dem man alles chornologisch runter schreiben kann. Anschließend, nach einigen Tests und Tweaks, wird das Ganze beispielsweise über eine FastAPI Schnittstelle deployed und verfügbar gemacht. “Unter der Haube” läuft aber nach wie vor das nicht optimierte Skript welches schlechte Prozesszeiten hat und im Verhältnis viel Rechenleistung benötigt.
Python-Code optimieren
In zwei konkreten Beispielen möchte ich Ihnen zeigen, wie die Nutzung von Packages wie Regex zu enormen Verlängerung der Prozesszeiten führen kann.
Beispiel zum Thema Regulärer Ausdruck
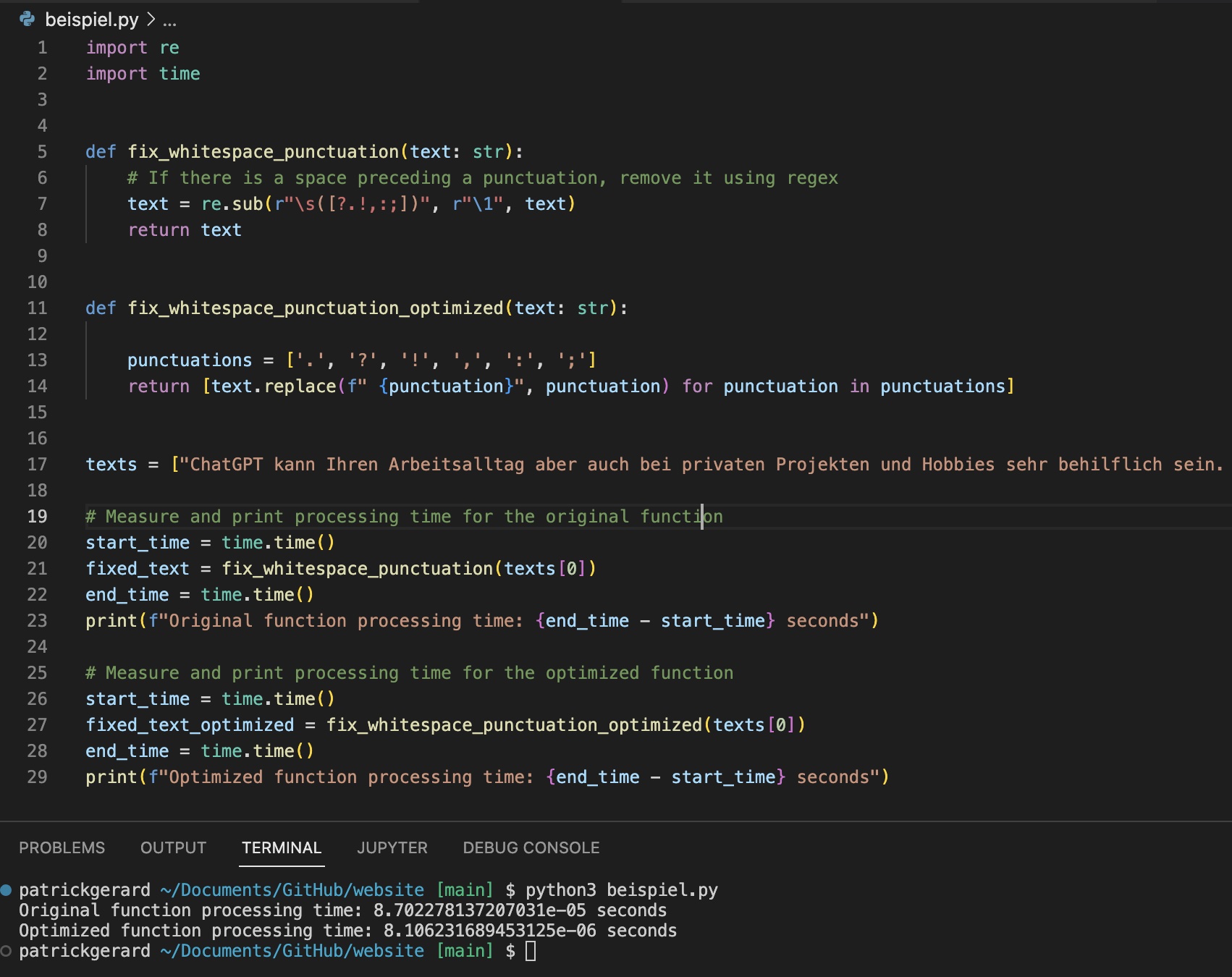
Die Ausführung des Skripts zeigt eine Effizienzsteigerung von circa 90 % bei der Verarbeitung eines Satzes mit 450 Zeichen.
Obwohl dieser kleine Teil des Algorithmus nur einen Bruchteil darstellt, kann beim Refactoring eines ML-Algorithmus eine solche Optimierung erhebliche Auswirkungen haben und durch geringfügige Änderungen entsprechend gute und bessere Ergebnisse erzielen.
Beispiel zum Thema Nested-For-Loop
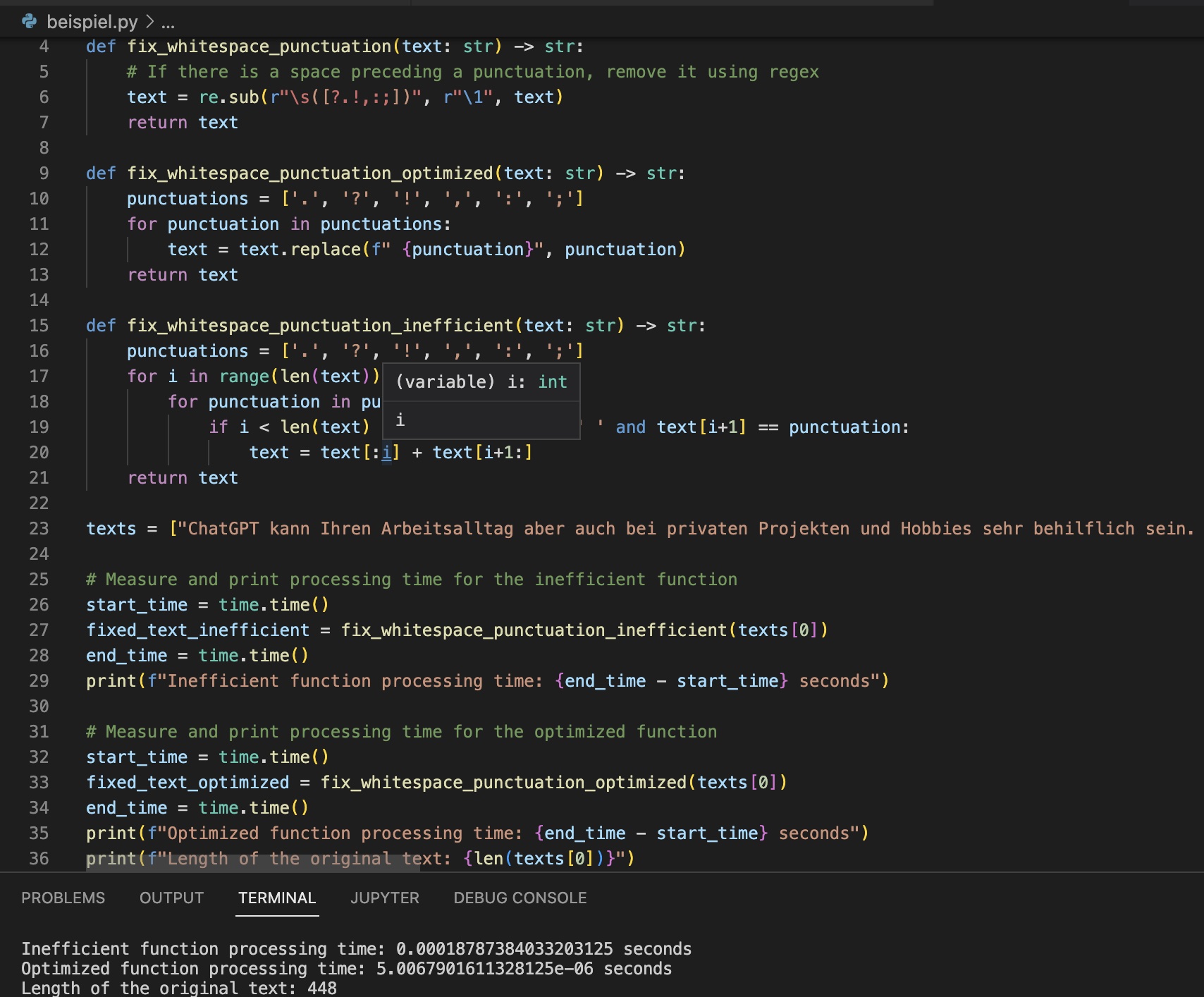
Die Ausführung der zwei Loops zeigt eine Differenz von über 90% bei der Verarbeitung desselben Satzes, verglichen mit dem Regex-Beispiel. Es ist daher wichtig, sogenannte Nested Loops zu vermeiden, da diese erheblich mehr Speicher beanspruchen und entsprechend langsamer sind.
Von einfach zu kompliziert
In den ersten zwei Beispielen habe ich Ihnen die einfachen Optimierungen von ML-Algorithmen vorgestellt. Schwierigere Ansätze wären beispielsweise das “parallele Batch oder Chunk bearbeiten” und vieles mehr. Diese Methoden werden genutzt um letzte Optimierungen vorzunehmen - anfangs können aber einfache Methoden wie die Verfolgung von Best-Practises bereits zehnfache Optimierungen bewirken.
Sie benötigen Hilfe bei der Optimierung von ML-Algorithmen?
Keyword-Tags
Machine Learning Algorithmen, Clean Code Python, Prozesszeiten verbessern, Python Best-Practises, performante ML-Algorithmen